Мы стали свидетелями новой технологической революции. Пока рано говорить, сравнима ли она с появлением ДВС или самолетов. Но очевидно, что нейронные сети радикально меняют методы работы в интернет-среде. Узнайте, как функционируют нейросети, какие вопросы можно задать ChatGPT и к чему здесь LLM в заголовке.
Что такое LLM
Большие языковые модели (LLM, Large Language Models) представляют собой масштабные нейронные сети глубокого обучения. «Матчасть», которая используется для обучения, — это гигантские объемы данных. LLM обрабатывает и анализирует источники, чтобы генерировать грамматически верный и достоверный текст. Основой LLM является трансформер — архитектура, построенная из двух ключевых компонентов: кодера и декодера.
Первый элемент анализирует текст, извлекая из него значения, и выявляет связи между словами и фразами. Декодер используется для генерации новых данных на основе усвоенной информации. Благодаря механизму самовнимания (self-attention), трансформеры способны понимать не только отдельные элементы текста, но и их контекст, включая сложные взаимосвязи между словами. Трансформеры обучаются на данных без прямого руководства.
В процессе самообучения модели изучают грамматические структуры, языковые закономерности и накапливают широкий спектр знаний. Архитектура трансформеров обеспечивает возможность обучать LLM на массивных источниках данных, таких как «Википедия», в которой содержится 57 млн статей.
Возможности существующих LLM
Большие языковые модели способны эффективно работать с минимальными исходными данными. Они широко используются в области генеративного ИИ (искусственного интеллекта) для создания оригинального контента.
Примеры крупных моделей и их возможности:
- GPT-3 от OpenAI имеет 175 миллиардов параметров. Нейросеть способна генерировать качественный текст, понимая и имитируя сложные языковые структуры. ChatGPT, разработанный на основе GPT-3, может обрабатывать запросы объёмом до сотен страниц текста.
- Jurassic-1 от AI21 Labs получил 178 миллиардов параметров, что в итоге позволило модели накопить словарный запас в 250 000 слов. Эта LLM эффективна в разговорном взаимодействии.
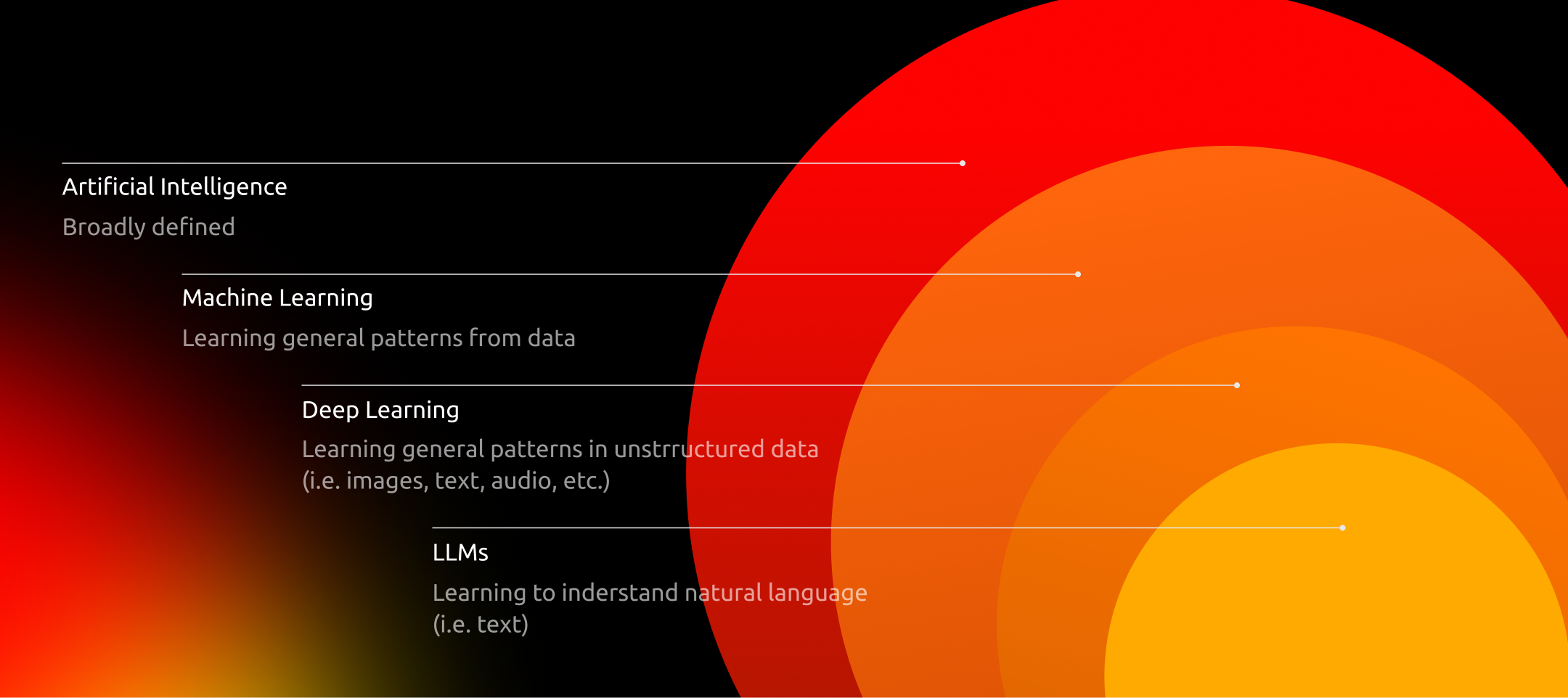
Принцип работы LLM
В основе работы LLM лежат методы глубокого машинного обучения. Это направление искусственного интеллекта обучает алгоритмы извлекать закономерности из данных и самостоятельно выявлять взаимосвязи и отличия в этих данных.
Это легко проиллюстрировать на примере. Если алгоритму показать только одно предложение: «Когда мы научимся летать, как птицы», то он запомнит, что перед «когда» запятая не требуется. Но покажите алгоритму тысячи примеров вида: «Мы отправили посылку, когда узнали точный адрес», — и машина запомнит правило, что необходимо ставить запятую перед «когда» в середине сложного предложения.
Несмотря на высокую степень автономности, глубокое обучение требует предварительной настройки и корректировок, которые выполняются специалистами для оптимизации работы модели.
Из чего состоит нейронная сеть
LLM строятся на основе искусственных нейронных сетей, которые имитируют работу человеческого мозга. Как и нейроны в нашем организме, эти сети состоят из узлов, которые обмениваются сигналами. Каждый нейрон обрабатывает информацию и передает ее дальше, если превышен определенный порог активации.

Структура нейронной сети включает:
- входной слой, который принимает данные;
- скрытые слои, где происходит обработка информации;
- выходной слой, генерирующий результат.
Такая многослойная архитектура позволяет моделям эффективно анализировать сложные взаимосвязи между данными.
Особый тип нейронных сетей, лежащий в основе LLM, — это трансформеры. Их ключевая особенность заключается в том, что они могут анализировать контекст. Это особенно важно для работы с человеческим языком, где значение слова или фразы часто зависит от окружающих элементов.
Трансформеры используют механизм внимания, который позволяет моделям учитывать связи между словами, даже если они находятся далеко друг от друга в тексте.
Это помогает понимать:
- как начало и конец предложения соотносятся друг с другом;
- как предложения внутри одного абзаца связаны смыслом.
Такой подход делает трансформеры более эффективными в обработке текстов по сравнению с другими моделями машинного обучения. Они способны учитывать сложный или неоднозначный контекст, а также интерпретировать новые комбинации слов и выражений. Проще говоря, современные LLM понимают концепцию юмора и оскорбительных выражений. ChatGPT и его альтернативы способны не только объяснять значение двусмысленных фраз, но и придумывать шутки.
Семантика и понимание
На определенном уровне LLM демонстрируют способность «понимать» язык. Они группируют слова и понятия по их значениям, опираясь на миллионы обработанных примеров.
Это позволяет моделям:
- работать с плохо структурированным текстом;
- генерировать осмысленные фразы на основе минимальных подсказок — промптов;
- адаптироваться к новым или ранее неизвестным контекстам.
Благодаря перечисленным возможностям LLM сегодня умеют многое: от генерации текстов для соцсетей до обработки редких диалектов.
Секрет эффективности LLM
Ранние подходы машинного обучения представляли слова в виде числовых таблиц, которые не могли учитывать взаимосвязи между словами, например, их синонимичные значения. Прорывом стало использование эмбеддингов слов — многомерных векторов, которые отражают семантическую близость между словами. В таком представлении слова с похожими значениями располагаются ближе друг к другу в векторном пространстве.
Архитектура трансформера позволяет преобразовывать текст в числовые векторы с помощью кодировщика, который анализирует контекст слов, их грамматические свойства и семантические взаимосвязи. Затем декодер использует эти данные для создания нового текста. Такой подход позволяет моделям генерировать оригинальные выходные данные, сохраняя логику и связность текста.
Открытые и проприетарные LLM
Большие языковые модели разделяются на две основные категории: модели с открытым исходным кодом и проприетарные решения. Модели с открытым исходным кодом доступны для использования широкому кругу лиц, которые могут модифицировать систему.
Прорывом в этом сегменте стала Llama 1, выпущенная в феврале 2023 года. Она доказала сообществу программистов, что по степени надежности и эффективности open source-модели могут сравняться с проприетарными решениями. За неполные два года появились альтернативные LLM с открытым исходным кодом: Mistral 7B, Falcon 180 и вариации Bert.
Как и в случае с любой open source-технологией, причиной критики становятся два аспекта:
- сложная интеграция в конкретную IT-систему;
- несоответствие требованиям безопасности и конфиденциальности.
Проприетарные модели, такие как GPT-4 от OpenAI, разрабатываются внутри компаний. Их исходный код и обучающие данные остаются неизвестными широкой общественности. Такие модели предназначены для корпоративного использования, поэтому каждое решение оптимизируется в соответствии с требованиями заказчика.
Вместе с запуском проприетарных моделей клиенты получают специализированную поддержку и уверенность в том, что обновления будут регулярными и в полном соответствии со стандартами конфиденциальности. Однако главным недостатком является высокая стоимость лицензирования и зависимость от поставщика.

Если подытожить, то модели с открытым исходным кодом подходят для экспериментов, изучения технологии и создания нишевых решений. Проприетарные LLM следует рассматривать в качестве «коробочного» решения для конкретной бизнес-задачи. И, как любая эксклюзивная разработка, такая модель стоит довольно дорого.
Могут ли LLM обучать сами себя и принимать решения
Ученые из Массачусетского технологического института (MIT) обнаружили, что LLM могут самостоятельно развивать внутренние модели реальности, которые помогают им лучше понимать инструкции. Например, в ходе эксперимента с головоломками Карела модель, первоначально генерировавшая случайные и некорректные команды, в итоге смогла создавать точные инструкции в 92,4 % случаев. Эти успехи показали, что, помимо обработки текста, LLM способны формировать внутренние концепции, даже если их этому не обучали напрямую.
Такой прогресс заставляет задуматься о границах возможностей языковых моделей. Используя методику «зондирования», исследователи изучили процесс «мышления» модели и обнаружили, что она развивала собственное понимание, как робот должен двигаться в ответ на команды. Это напоминает процесс освоения речи ребенком: сначала хаотичные попытки, затем постепенное усвоение синтаксиса и, наконец, формирование смысла, что приводит к точным и эффективным результатам.
Обучение LLM включает такие этапы:
- предварительное обучение на огромных объемах данных.
- доработка запросов (prompt-engineering).
- тонкая настройка для следования инструкциям (fine-tuning).
- адаптация выходных данных к человеческим ценностям с помощью методов, таких как RLHF (Reinforcement Learning From Human Feedback, обучение с подкреплением на основе отзывов людей) или PEFT (Parameter Efficient Fine-Tuning, эффективная настройка параметров).
Первый этап требует особенно больших данных. Например, модель Llama 3 использует более 15 триллионов токенов. Однако растущий дефицит текстовых данных вынуждает исследователей искать альтернативы, такие как обучение меньших моделей на результатах работы более крупных.
Преимущества и недостатки LLM
Нынешние общедоступные большие языковые модели — это удобный, но не безупречный инструмент. Они помогают в решении многих задач, о чем мы скажем дальше. При этом важно понимать ограничения, свойственные LLM.
Достоинства LLM
- Эффективность и производительность. LLM способны автоматизировать сложные задачи, такие как генерация кода, анализ программных артефактов или помощь в принятии решений, что сокращает ручной труд и ускоряет процессы.
- Масштабируемость. Способность LLM работать с большими объемами текстов и данных делает их полезными для обработки обширной документации.
- Применимость к разным задачам. От анализа художественных текстов до генерации кода и прототипирования — LLM помогают в маркетинге, программировании, журналистике и во многих других сферах.
- Доступность и простота использования. Облачные платформы и API делают LLM доступными для широкого круга пользователей, в том числе нетехнических специалистов. В интернете можно найти много примеров из жизни, когда люди, незнакомые с каким-либо языком программирования, с помощью ChatGPT создавали коды несложных приложений.
Непрерывное обучение.Возможность дообучения позволяет моделям адаптироваться к новым данным.
Недостатки LLM
- Неточности и ошибки. LLM могут выдавать неверные ответы. Ошибки возникают как из-за неверно построенной логической связи, так и из-за непонимания широкого контекста при сложном запросе.
- «Проблема взаимопонимания». Для эффективной работы с LLM требуется навык создания точных подсказок, или промптов и анализа результатов. На промпт уровня ключевой фразы в Google LLM выдаст корректный ответ. Но если вкратце попросить ChatGPT составить анализ сложного явления, высока вероятность получить поверхностное описание с фактическими ошибками.
- Высокая стоимость. Использование LLM, включая обучение, настройку и эксплуатацию, — ресурсоемкая задача, которая не по силам для многих коммерческих организаций.
- Ограниченные знания. LLM ограничены данными, на которых они были обучены. Например, в конце 2024 года самые свежие данные для ChatGPT датируются январем 2022.
- Использование в незаконных схемах. Хотя разработчики LLM постоянно напоминают о важности фактора этики, в интернете можно найти примеры, как нейросети подсказывали пользователям идеи с преступными схемами.
- Переоцененные ожидания. В данном случае, проблема заключается в человеческом факторе. Пользователи, которые не перепроверяют данные, полученные от LLM, рискуют допустить грубую ошибку в работе.
Где и как применяются LLM
Большие языковые модели помогают в решении рутинных задач и в ситуациях, когда необходимо много времени потратить на изучение данных. Если проверять корректность полученных данных, из ChatGPT и его аналогов получится отличный ассистент, способный, в частности, коммуницировать с людьми.
Как использовать LLM:
- создавать контент, особенно, в сфере маркетинга, блоггинга и журналистики;
- общаться с клиентами через чат-боты;
- извлекать данные из текстовых, аудио- и видеофайлов;
- оптимизировать процессы, в которых необходимо обработать большие массивы данных.
Основные сценарии использования LLM
- Анализ данных: от интернет-опросов до вертикальных видео. Изучение подобной информации позволяет бизнесу достаточно быстро и относительно дешево получить маркетинговое исследование.
- Улучшение клиентского опыта. Поскольку LLM отлично справляются с решением рутинных задач, их удобно встраивать в чат-боты. Применение LLM в виртуальных помощниках позволит улучшить клиентский опыт, не прибегая к использованию дорогостоящей человеческой силы.
- LLM ускоряют процесс создания черновиков, помогая журналистам и маркетологам сосредоточиться на креативных аспектах текстов.
- Перевод и локализация в реальном времени как текстов, так и аудио — идеальное решение и для крупной международной компании, и для туриста в незнакомой стране.
- Если правильно сформулировать задачу для LLM, можно получить персонализированные учебные материалы. Тот же ChatGPT в совершенстве владеет многими языками. И поскольку он воспроизводит речь, человек может общаться с машиной не только через текст, но и в «живом» диалоге.
- Финансовые услуги: анализ транзакций и выявление подозрительных схем, понимание рыночных трендов для принятия инвестиционных решений.
- Кибербезопасность: анализ данных для выявления угроз.
Итоги
Большие языковые модели (LLM), на которых построен ChatGPT и его аналоги, способны качественно воспринимать информацию: через текст, аудио и видео. Особенность систем в том, что информация не только извлекается по указанным параметрам, но и обрабатывается в процессе машинного обучения. Модели способны анализировать и систематизировать данные по тому же принципу, как это делают люди.
Успешное развитие LLM и появление общедоступных нейросетей облегчает рабочие и учебные процессы. Вместе с тем, следует учитывать ограниченные способности нейросетей. Проверка полученных данных человеком всё еще остается ключевым элементом генерации контента.